
SIIBGauss – [download]
SIIBGauss is an intrusive instrumental intelligibility metric based on the orginal SIIB metric (see below). The difference between SIIBGauss and SIIB is that SIIBGauss estimates the capacity of a Gaussian communication channel, whereas SIIB uses a non-parametric mutual information estimator. Both algorithms have state-of-the-art performance, but SIIBGauss takes less time to compute.
Relevant publications:
- S. Van Kuyk, W. B. Kleijn, and R. C. Hendriks, ‘An instrumental intelligibility metric based on information theory’, IEEE Signal Processing Letters, 2018.
- S. Van Kuyk, W. B. Kleijn, and R. C. Hendriks, ‘An evaluation of intrusive instrumental intelligibility metrics’, IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018.
Speech intelligibility in bits – [download] (updated on 3/10/17)
Speech intelligibility in bits (SIIB) is an intrusive instrumental intelligibility metric based on information theory. Given a clean acoustic speech signal and a distorted acoustic speech signal, SIIB estimates the amount of information (in bits per second) shared between the signals. SIIB is strongly correlated with intelligibility listening test scores, and thus can be used to quickly evaluate the performance of a communication system. Demo:
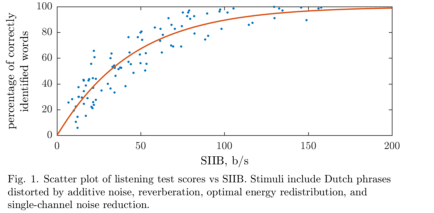
Relevant publications:
- S. Van Kuyk, W. B. Kleijn, and R. C. Hendriks, ‘An instrumental intelligibility metric based on information theory’, IEEE Signal Processing Letters, 2018.
- S. Van Kuyk, W. B. Kleijn, and R. C. Hendriks, ‘An evaluation of intrusive instrumental intelligibility metrics’, IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2018.
Optimal energy redistribution for speech enhancement – [download]
This algorithm aims to improve the intelligibility of a noisy speech signal without increasing the energy of the speech. The algorithm requires the clean speech and the noise statistics as inputs. A linear filter that optimally redistributes energy according to a mutual information criterion is applied to the clean speech. Demo: [original] [enhanced]
Relevant publication: W.B. Kleijn and R.C. Hendriks; “A simple model of speech communication and its application to intelligibility enhancement”, IEEE Signal Processing Letters, 2015
Vowel generator – [download]
This vowel generator synthesises an audio signal that consists of a random sequence of vowels. Each time the function is run, vocal tract model parameters are randomly selected to simulate talker variability. This function can be used to generate an infinite amount of training data for testing small-scale automatic speech recognition systems. Demo:
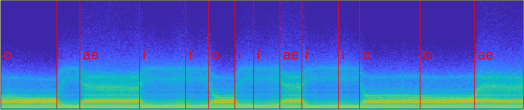
Speech synthesis from short-time magnitude spectra – [download]
Given a sequence of short-time magnitude spectra, this code synthesizes a speech signal using the Griffin & Lim algorithm. Importantly, no phase information is required.
Relevant publication: D. W. Griffin and J. S. Lim; “Signal estimation from modified short-time Fourier transform”, IEEE Transactions on Acoustics, Speech, and Signal Processing, 1984.
Gaussian Mixture Model – [download]
A Gaussian Mixture Model (GMM) is a parametric probabilistic model for representing sub-populations within a population. GMMs can be used for clustering data and approximating multi-modal probability distributions. This code contains two algorithms for fitting a GMM to a data set. The algorithms are known as Expectation-Maximization, and Variational Inference. Demo:
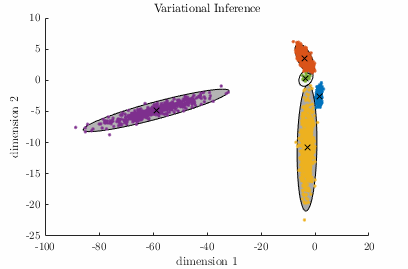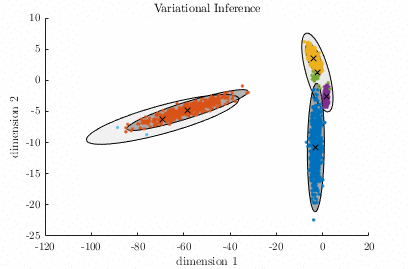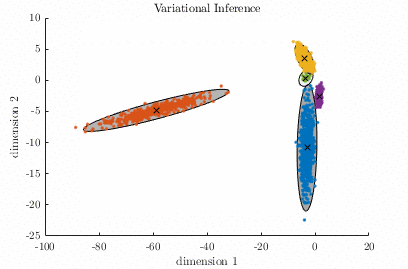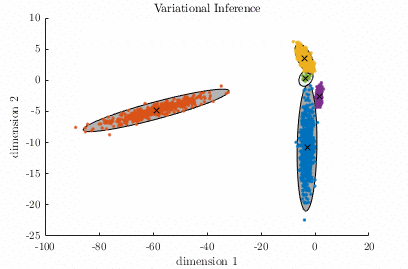
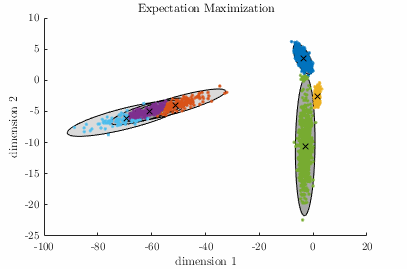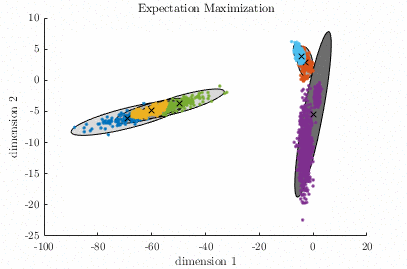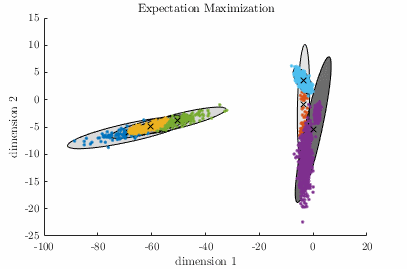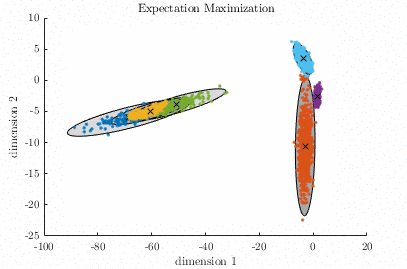
Relevant publication: C. M. Bishop; “Pattern Recognition and Machine Learning”, Springer, 2006
